Now, we have an optimization problem where we want to change the models weights to maximize the log-likelihood. Webnegative gradient, calledexact line search: t= argmin s 0 f(x srf(x)) semi-log plot 9.3 Gradient descent method 473 k f (x (k))! Thanks for contributing an answer to Cross Validated! Therefore, gradient ascent would produce a set of theta that maximizes the value of a cost function. For step 2, we must find a way to relate our linear predictor to our parameter p. Since p is between 0 and 1 and can be any real number, a natural choice is the log-odds. This article shows how to implement GLMs from scratch using only Pythons Numpy package. Of course, I ignored the chain rule for that one! Find centralized, trusted content and collaborate around the technologies you use most. Because I don't see you using $f$ anywhere. \hat{\mathbf{w}}_{MAP} = \operatorname*{argmax}_{\mathbf{w}} \log \, \left(P(\mathbf y \mid X, \mathbf{w}) P(\mathbf{w})\right) &= \operatorname*{argmin}_{\mathbf{w}} \sum_{i=1}^n \log(1+e^{-y_i\mathbf{w}^T \mathbf{x}_i})+\lambda\mathbf{w}^\top\mathbf{w}, Any log-odds values equal to or greater than 0 will have a probability of 0.5 or higher. Theoretically I understand the implementation and I was able to solve it by hand on a paper but I am finding it hard to implement on python while using some simulated data (as shown in my code). /Font << /F50 4 0 R /F52 5 0 R /F53 6 0 R /F35 7 0 R /F33 8 0 R /F36 9 0 R /F15 10 0 R /F38 11 0 R /F41 12 0 R >> Now for step 3, find the negative log-likelihood. Is there a connector for 0.1in pitch linear hole patterns? Find centralized, trusted content and collaborate around the technologies you use most. $P(y_k|x) = \text{softmax}_k(a_k(x))$. Connect and share knowledge within a single location that is structured and easy to search. MathJax reference. d/db(y_i \cdot \log p(x_i)) &=& \log p(x_i) \cdot 0 + y_i \cdot(d/db(\log p(x_i))\\ Then the relevant quantities are the vectors $$ ?cvC=4]3in4*/9Dd Both methods can also be solved less efficiently using a more general optimization algorithm such as stochastic gradient descent. 2 Warmup with R. 2.1 Read in the Data and Get the Variables. A Medium publication sharing concepts, ideas and codes. Therefore, the initial parameter values would gradually converge to the optima as the maximum is reached. Its gradient is supposed to be: $_(logL)=X^T ( ye^{X}$) What is an epoch? This is the Gaussian approximation for LR. If the dataset is massive, the batch approach might not be ideal. This is the process of gradient descent. In Figure 1, the first equation is the sigmoid function, which creates the S curve we often see with logistic regression. This represents a feature vector. Step 3: lets find the negative log-likelihood. (The article is getting out of hand, so I am skipping the derivation, but I have some more details in my book . Maybe, but I just noticed another mistake: when you compute the derivative of the first term in $L(\beta)$. \end{align*}, \begin{align*} Use MathJax to format equations. We start with picking a random intercept or, in the equation, y = mx + c, the value of c. We can consider the slope to be 0.5. The answer is gradient descent. WebThe first component of the cost function is the negative log likelihood which can be optimized using the contrastive divergence approximation and the second component is a sparsity regularization term which can be optimized using gradient descent. The probabilities are turned into target classes (e.g., 0 or 1) that predict, for example, success (1) or failure (0). A2 We can also visualize the parameters converging for every epoch iteration. We also examined the cross-entropy loss function using the gradient descent algorithm. Training finds parameter values w i,j, c i, and b j to minimize the cost. Your home for data science. There are only a few lines of code changes and then the code is ready to go (see # changed in code below). Finally for step 4, lets see if we can minimize this loss function analytically. In other words, you take the gradient for each parameter, which has both magnitude and direction. differentiable or subdifferentiable).It can be regarded as a stochastic approximation of gradient descent optimization, since it replaces the actual gradient (calculated from the entire data set) by The code below generated an accuracy score of 79.8%. Stats Major at Harvard and Data Scientist in Training, # Generate response as function of X and beta, # Generate response as a function of the same X and beta, Linearity between the outcome and input variables, Identify a loss function. Suppose we have the following training data where each x is a D-dimensional vector: We first write as a linear function of x for each observation n = 1, , N: Then we connect to with the link function: To fit the GLM, we are actually just finding estimates for the s: from these, we obtain estimates of , which leads immediately to an estimate for , which then gives us an estimated distribution for Y! dL &= y:d\log(p) + (1-y):d\log(1-p) \cr Now if we take the log, e obtain The conditional data likelihood $P(\mathbf y \mid X, \mathbf{w})$ is the probability of the observed values $\mathbf y \in \mathbb R^n$ in the training data conditioned on the feature values \(\mathbf{x}_i\). \end{align*}, $$\frac{\partial}{\partial \beta} L(\beta) = \sum_{i=1}^n \Bigl[ y_i \cdot (p(x_i) \cdot (1 - p(x_i))) + (1 - y_i) \cdot p(x_i) \Bigr]$$. However, since most deep learning frameworks implement stochastic gradient descent, lets turn this maximization problem into a minimization problem by negating the log-log likelihood: Now, how does all of that relate to supervised learning and classification? &= (y-p):df \cr WebIt is a stochastic Variable Metric ForwardBackward algorithm, which allows approximate preconditioned forward operator and uses a variable metric proximity operator as the backward operator; it also proposes a mini-batch strategy with variance reduction to address the finite sum setting. Our goal is to minimize this negative log-likelihood function. (13) No, Is the Subject Are \frac{\partial}{\partial w_{ij}}\text{softmax}_k(z) & = \sum_l \text{softmax}_k(z)(\delta_{kl} - \text{softmax}_l(z)) \times \frac{\partial z_l}{\partial w_{ij}} }$$. Would spinning bush planes' tundra tires in flight be useful? Lets walk through how we get likelihood, L(). This means, for every epoch, the entire training set will pass through the gradient algorithm to update the parameters. Group set of commands as atomic transactions (C++). And because the response is binary (e.g., True vs. False, Yes vs. No, Survived vs. Not Survived), the response variable will have a Bernoulli distribution. P(i~QA0yWL:KLkb+c?6D>DOYQz=x$~E eP"T(NstZFnpl JKoG-4M .hZkdx9CWj.gdJM1Kr+.fD XX@Vjjs R TM'hqk`(o2rWP8tt4cSHjP~7Nb ! Each feature in the vector will have a corresponding parameter estimated using an optimization algorithm. stream &= \big(y-p\big):X^Td\beta \cr Once the partial derivative (Figure 10) is derived for each parameter, the form is the same as in Figure 8. When it comes to modeling, often the best way to understand whats underneath the hood is to build the car yourself. However, as data sets become large logistic regression often outperforms Naive Bayes, which suffers from the fact that the assumptions made on $P(\mathbf{x}|y)$ are probably not exactly correct. The function we optimize in logistic regression or deep neural network classifiers is essentially the likelihood: WebSince products are numerically brittly, we usually apply a log-transform, which turns the product into a sum: \(\log ab = \log a + \log b\), such that. Once again, this function has no closed form solution, but we can use Gradient Descent on the negative log posterior $\ell(\mathbf{w})=\sum_{i=1}^n \log(1+e^{-y_i\mathbf{w}^T \mathbf{x}_i})+\lambda\mathbf{w}^\top\mathbf{w}$ to find the optimal parameters $\mathbf{w}$. We now know that log-odds is the output of the linear regression function, and this output is the input in the sigmoid function. Connect and share knowledge within a single location that is structured and easy to search. Thanks for contributing an answer to Stack Overflow! WebHardware advances have meant that from 1991 to 2015, computer power (especially as delivered by GPUs) has increased around a million-fold, making standard backpropagation feasible for networks several layers deeper than when The negative log-likelihood \(L(\mathbf{w}, b \mid z)\) is then what we usually call the logistic loss. Still, I'd love to see a complete answer because I still need to fill some gaps in my understanding of how the gradient works. Note that our loss function is proportional to the sum of the squared errors. Can a frightened PC shape change if doing so reduces their distance to the source of their fear? How do I concatenate two lists in Python? Is RAM wiped before use in another LXC container? Thus, we will end up with four partial derivatives for every instance in the training set. You will also come across lowercase bolded non-italic x. Because the log-likelihood function is concave, eventually, the small uphill steps will reach the global maximum. In standardization, we take the mean for each numeric feature and subtract the mean from each value. \end{aligned}, Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. /Contents 3 0 R In Logistic Regression we do not attempt to model the data distribution $P(\mathbf{x}|y)$, instead, we model $P(y|\mathbf{x})$ directly. so that we can calculate the likelihood as follows: Is there a connector for 0.1in pitch linear hole patterns? Here, we use the negative log-likelihood. While this modeling approach is easily interpreted, efficiently implemented, and capable of accurately capturing many linear relationships, it does come with several significant limitations. Asking for help, clarification, or responding to other answers. The process is the same as the process described in the gradient ascent section above. Can a frightened PC shape change if doing so reduces their distance to the source of their fear? \(L(\mathbf{w}, b \mid z)=\frac{1}{n} \sum_{i=1}^{n}\left[-y^{(i)} \log \left(\sigma\left(z^{(i)}\right)\right)-\left(1-y^{(i)}\right) \log \left(1-\sigma\left(z^{(i)}\right)\right)\right]\). So this is extremely intuitive, the regularization takes positive coefficients and decreases them a little bit, negative coefficients and increases them a little bit. This course touches on several key aspects a practitioner needs in order to be able to aply ML to business problems: ML Algorithms intuition. I am afraid, that my solution is wrong, because in Hasties The Elements of Statistical Learning on page 120 it says the gradient is: $$\sum_{i = 1}^N x_i(y_i - p(x_i;\beta))$$. What is the name of this threaded tube with screws at each end? Sleeping on the Sweden-Finland ferry; how rowdy does it get? By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. Do I really need plural grammatical number when my conlang deals with existence and uniqueness? With the above code, we have prepared the train input dataset. We reached the minimum after the first epoch, as we observed with maximum log-likelihood. Can I disengage and reengage in a surprise combat situation to retry for a better Initiative? Is standardization still needed after a LASSO model is fitted? There are several metrics to measure performance, but well take a quick look at accuracy for now. Logistic regression, a classification algorithm, outputs predicted probabilities for a given set of instances with features paired with optimized parameters plus a bias term. This is for the bias term. \end{aligned}$$. I tried to implement the negative loglikelihood and the gradient descent for log reg as per my code below. rev2023.4.5.43379. By maximizing the log-likelihood through gradient ascent algorithm, we have derived the best parameters for the Titanic training set to predict passenger survival. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. \(\sigma\) is the logistic sigmoid function, \(\sigma(z)=\frac{1}{1+e^{-z}}\). First, note that S(x) = S(x)(1-S(x)): To speed up calculations in Python, we can also write this as. >> endobj Lets examine what is going on during each epoch interval. Does Python have a ternary conditional operator? EDIT: your formula includes a y! We often hear that we need to minimize the cost or the loss function. Hasties The Elements of Statistical Learning, Improving the copy in the close modal and post notices - 2023 edition, Deriving the gradient vector of a Probit model, Vector derivative with power of two in it, Gradient vector function using sum and scalar, Take the derivative of this likelihood function, role of the identity matrix in gradient of negative log likelihood loss function, Deriving max. For a lot more details, I strongly suggest that you read this excellent book chapter by Tom Mitchell. Start by taking the derivative with respect to and setting it equal to 0. Your home for data science. How many unique sounds would a verbally-communicating species need to develop a language? \frac{\partial}{\partial w_{ij}} L(w) & = \sum_{n,k} y_{nk} \frac{1}{\text{softmax}_k(Wx)} \times \text{softmax}_k(z)(\delta_{ki} - \text{softmax}_i(z)) \times x_j T6.pdf - DSA3102 Convex Optimization Tutorial 6 1. Not that we assume that the samples are independent, so that we used the following conditional independence assumption above: \(\mathcal{p}(x^{(1)}, x^{(2)}\vert \mathbf{w}) = \mathcal{p}(x^{(1)}\vert \mathbf{w}) \cdot \mathcal{p}(x^{(2)}\vert \mathbf{w})\). endstream We first need to know the definition of odds the probability of success divided by failure, P(success)/P(failure). We dont want the learning rate to be too low, which will take a long time to converge, and we dont want the learning rate to be too high, which can overshoot and jump around. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. This is the matrix form of the gradient, which appears on page 121 of Hastie's book. $\{X,y\}$. Viewed 15k times 9 $\begingroup$ role of the identity matrix in gradient of negative log likelihood loss function. In ordinary linear regression, we treat our outcome variable as a linear combination of several input variables plus some random noise, typically assumed to be Normally distributed. Also, note your final line can be simplified to: $\sum_{i=1}^n \Bigl[ p(x_i) (y_i - p(x_i)) \Bigr]$. To find the values of the parameters at minimum, we can try to find solutions for \(\nabla_{\mathbf{w}} \sum_{i=1}^n \log(1+e^{-y_i \mathbf{w}^T \mathbf{x}_i}) =0\). Therefore, the odds are 0.5/0.5, and this means that odds of getting tails is one. Thanks for reading! im6tF^2:1L>%KD[mBR]}V1B)A6M<7, +#uJXqQ@Mx.tpn Instead of maximizing the log-likelihood, the negative log-likelihood can be min-imized. Im not sure which ones are you referring to, this is how it looks to me: Deriving Gradient from negative log-likelihood function, Improving the copy in the close modal and post notices - 2023 edition. Seeking Advice on Allowing Students to Skip a Quiz in Linear Algebra Course. For step 3, find the negative log likelihood. Did Jesus commit the HOLY spirit in to the hands of the father ? \end{aligned}$$ We are now equipped with all the components to build a binary logistic regression model from scratch. /Length 1828 \begin{aligned} The results from minimizing the cross-entropy loss function will be the same as above. How can I "number" polygons with the same field values with sequential letters. We also need to define the sigmoid function in code because this will generate our probabilities. Relates to going into another country in defense of one's people, Deadly Simplicity with Unconventional Weaponry for Warpriest Doctrine. \end{align} This term is then divided by the standard deviation of the feature. Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide, Loglikelihood and gradient function implementation in Python. Webmode of the likelihood and the posterior, while F is the negative marginal log-likelihood. Can anyone guide me in how this can be implemented? The next step is to transform odds into log-odds. Convexity, Gradient Descent, and Log-Likelihood We can now sum up the reasoning that we conducted in this article in a series of propositions that represent the theoretical inference that weve conducted: The error function is the function through which we optimize the parameters of a machine learning model Lets take a look at the cross-entropy loss function being minimized using gradient descent. Luke 23:44-48. Webthe empirical negative log likelihood of S(\log loss"): JLOG S (w) := 1 n Xn i=1 logp y(i) x (i);w I Gradient? We covered a lot of ground, and we are now at the last mile of understanding logistic regression at a high level. On macOS installs in languages other than English, do folders such as Desktop, Documents, and Downloads have localized names? To subscribe to this RSS feed, copy and paste this URL into your RSS reader. = g(). However, in the case of logistic regression (and many other complex or otherwise non-linear systems), this analytical method doesnt work. Instead, we resort to a method known as gradient descent, whereby we randomly initialize and then incrementally update our weights by calculating the slope of our objective function. )$. An essential takeaway of transforming probabilities to odds and odds to log-odds is that the relationships are monotonic. How many sigops are in the invalid block 783426? It is important to note that likelihood is represented as the likelihood of while probability is designated as the probability of Y. Why did the transpose of X become just X? This is called the Maximum Likelihood Estimation (MLE). Based on Y (0 or 1), one of the terms in the dot product becomes 1 and drops off. It only takes a minute to sign up. WebLog-likelihood gradient and Hessian. Dealing with unknowledgeable check-in staff. Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. Thanks for contributing an answer to Cross Validated! These make up the gradient vector. 2 0 obj << rev2023.4.5.43379. I have seven steps to conclude a dualist reality. Now lets fit the model using gradient descent. exact l.s. We have all the pieces in place. https://www.cs.cornell.edu/courses/cs4780/2018fa/lectures/lecturenote06.html log L = \sum_{i=1}^{M}y_{i}x_{i}+\sum_{i=1}^{M}e^{x_{i}} +\sum_{i=1}^{M}log(yi!). Typically, in scenarios with little data and if the modeling assumption is appropriate, Naive Bayes tends to outperform Logistic Regression. explained probabilities and likelihood in the context of distributions. Therefore, the negative of the log-likelihood function is used, referred to generally as a Negative Log-Likelihood (NLL) function. Negative log likelihood function is given as: $$ log L = \sum_{i=1}^{M}y_{i}x_{i}+\sum_{i=1}^{M}e^{x_{i}} +\sum_{i=1}^{M}log(yi!). The is the learning rate determining how big a step the gradient ascent algorithm will take for each iteration. d\log(1-p) &= \frac{-dp}{1-p} \,=\, -p\circ df \cr 2 Considering the following functions I'm having a tough time finding the appropriate gradient function for the log-likelihood as defined below: ak(x) = Di = 1wki First, we need to scale the features, which will help with the convergence process. Understanding the mechanics of stochastic and mini-batch gradient descent algorithms will be much more helpful. So basically I used the product and chain rule to compute the derivative. WebPlot the value of the parameters KMLE, and CMLE versus the number of iterations. Keep in mind that there are other sigmoid functions in the wild with varying bounded ranges. The task is to compute the derivative $\frac{\partial}{\partial \beta} L(\beta)$. In this case, the x is a single instance (an observation in the training set) represented as a feature vector. GLMs can be easily fit with a few lines of code in languages like R or Python, but to understand how a model works, its always helpful to get under the hood and code it up yourself. In Naive Bayes, we first model $P(\mathbf{x}|y)$ for each label $y$, and then obtain the decision boundary that best discriminates between these two distributions. MA. /Filter /FlateDecode \frac{\partial L}{\partial\beta} &= X\,(y-p) \cr The terms in the case of logistic regression will also come across lowercase non-italic. The context of distributions my conlang deals with existence and uniqueness ) $ of transforming to... Parameter, which appears on page 121 of Hastie 's book to Skip a Quiz in Algebra. Concepts, ideas and codes can gradient descent negative log likelihood this loss function is used, referred to generally as a log-likelihood. Partial derivatives for every epoch iteration, this analytical method doesnt work their! Also come across lowercase bolded non-italic x would a verbally-communicating species need to define the sigmoid in. Src= '' https: //www.youtube.com/embed/KYuw0eBEHpE '' title= '' 5 algorithm will take each! Of x become just x wild with varying bounded ranges we observed with maximum log-likelihood regression at a high.! Performance, but well take a quick look at accuracy for now components to a. < iframe width= '' 560 '' height= '' 315 '' src= '' http: //www.dsplog.com/db-install/wp-content/uploads/2011/11/convergence_batch_stochastic_gradient_descent.png alt=... $ ) what is going on during each epoch interval as above /FlateDecode {... At each end the name of this threaded tube with screws at each end see if we calculate! Iframe width= '' 560 '' height= '' 315 '' src= '' https: //www.youtube.com/embed/N-TTUvirIXM '' title= '' 7.2.4 four derivatives! There a connector for 0.1in pitch linear hole patterns only if its eigenvalues are all non-negative Alternatively a... Hastie 's book start by taking the derivative creates the S curve we often with. And we are now at the last mile of understanding logistic regression asking for help clarification! Ascent algorithm will take for each numeric feature and subtract the mean from each.. With screws at each end < img src= '' http: //www.dsplog.com/db-install/wp-content/uploads/2011/11/convergence_batch_stochastic_gradient_descent.png '' alt= '' '' <... Can calculate the likelihood as follows: is there a connector for pitch... Parameters KMLE, and b j to minimize the cost or the loss analytically! Also come across lowercase bolded non-italic x ) what is the negative loglikelihood the... Minimum after the first epoch, as we observed with maximum log-likelihood and easy to search how does! Tundra tires in flight be useful in flight be useful important to note that our loss function be! An epoch epoch, as we observed with maximum log-likelihood by Tom Mitchell for step 3: find... The likelihood and the gradient ascent algorithm will take for each numeric feature and the! Single instance ( an observation in the context of distributions likelihood and posterior... The Sweden-Finland ferry ; how rowdy does it get, or responding to other answers and this that. F is the learning rate determining how big a step the gradient for each parameter, which both! } & = X\, ( y-p ) have a corresponding parameter estimated using an optimization problem where we to... The source of their fear in another LXC container outperform logistic regression and... Parameter estimated using an optimization algorithm spinning bush planes ' tundra tires in flight be useful for! On the Sweden-Finland ferry ; how rowdy does it gradient descent negative log likelihood can also visualize parameters... A high level we will end up with four partial derivatives for every epoch iteration is an?! Me in how this can be implemented why did the transpose of become. And paste this URL into your RSS reader at the last mile of understanding logistic (! How many unique sounds would a verbally-communicating species need to develop a language bolded non-italic.... 4, lets see if we can minimize this negative log-likelihood function 121..., and b j to minimize the cost or the loss function using the gradient ascent will! Technologists share private knowledge with coworkers, Reach developers & technologists share private knowledge with coworkers, Reach developers technologists. Just x training set ) represented as a feature vector site design / logo 2023 Stack Exchange ;... From minimizing the cross-entropy loss function will be the same as above the models weights maximize... Implement GLMs from scratch using only Pythons Numpy package ascent would produce set! Single instance ( an observation in the wild with varying bounded ranges there are several metrics to measure,... Descent for log reg as per my code below keep in mind that there several... Minimize this loss function analytically a single location that is structured and easy to search take for numeric. Converging for every instance in the training set will have a corresponding parameter estimated an... Is a single location that is structured and easy to search, y-p! Maximizes the value of a cost function the technologies you use most align * }, \begin { *!, which creates the S curve we often hear that we need to develop a?. Be ideal collaborate around the technologies you use most the posterior, while F is the learning rate determining big. Will also come across lowercase bolded non-italic x, Documents, and j... Of distributions will end up with four partial derivatives for every epoch iteration likelihood in the context of distributions HOLY! Gradient gradient descent negative log likelihood each numeric feature and subtract the mean for each parameter, which has both magnitude and.. Of getting tails is one high level the dataset is massive, batch... We reached the minimum after the first equation is the learning rate determining how a. Will have a corresponding parameter estimated using an optimization problem where we want to change the models weights to the! > endobj lets examine what is going on during each epoch interval instance in the of. Change if doing so reduces their distance to the source of their fear are non-negative... Of ground, and b j to minimize the cost maximizes the value of cost. Such as Desktop, Documents, and we are now equipped with all the components to build the car.... More details, I ignored the gradient descent negative log likelihood rule to compute the derivative $ \frac { \partial } { \partial {... Ye^ { x } $ ) what is an epoch we also need to develop a?! Maximum is reached and drops off also come across lowercase bolded non-italic x and this means that odds of tails... Parameters KMLE, and this means that odds of getting tails is one is standardization still after... How many sigops are in the vector will have a corresponding parameter using! Ideas and codes { softmax } _k ( a_k ( x ) ) $ ( logL =X^T! Or the loss function is proportional to the hands of the likelihood and the posterior, while F the! When it comes to modeling, often the best way to understand whats the... In the Data and get the Variables their distance to the optima the. Which appears on page 121 of Hastie 's book how to implement the negative log likelihood _. \Beta } L ( \beta ) $ & = X\, ( )! What is going on during each epoch interval align } this term is then divided by standard! Have derived the best parameters for the Titanic training set to predict passenger survival Medium sharing... Curve we often hear that we can calculate the likelihood of while probability is designated as the maximum Estimation! Equal to 0 $ we are now equipped with all the components to a. Worldwide, loglikelihood and gradient function implementation in Python Tom Mitchell and uniqueness,... In this case, the negative log-likelihood are monotonic for help, clarification, or responding to other answers tends... Little Data and get the Variables, Documents, and this means that odds of getting tails is one for... Equipped with all the components to build a binary logistic regression at a high level Desktop, Documents, Downloads. In flight be useful of while probability is designated as the maximum is reached of this threaded tube with at. Of getting tails is one softmax } _k ( a_k ( x ) $! Lot more details, I ignored the chain rule for that one of course I. Algebra course we want to change the models weights to maximize the log-likelihood that. To the sum of the gradient for each iteration we are now equipped all. If we can minimize this negative log-likelihood function is proportional to the hands of parameters! Installs in languages other than English, do folders such as Desktop, Documents, Downloads... Connector for 0.1in pitch linear hole patterns mini-batch gradient descent algorithm macOS installs languages... Function using the gradient, which appears on page 121 of Hastie 's book: lets find negative. 121 of Hastie 's book the dot product becomes 1 and drops off into your RSS.. The number of iterations which appears on page 121 of Hastie 's book < img src= '' https: ''... Is reached be implemented in the vector will have a corresponding parameter estimated using an optimization problem we. End up with four partial derivatives for every instance in the wild with varying bounded ranges feature! Get likelihood, L ( \beta ) $ therefore, the negative log likelihood around the technologies you use.. Figure 1, the initial parameter values w I, and we are equipped! \Partial } { \partial\beta } & = X\, ( y-p ) reached the minimum after the first equation the! Is one Inc ; user contributions licensed under CC BY-SA as Desktop,,! Finds parameter values would gradually converge to the source of their fear the optima as the likelihood the. Essential takeaway of transforming probabilities to odds and odds to log-odds is that gradient descent negative log likelihood relationships are monotonic,. Kmle, and Downloads have localized names webmode of the feature L } { \partial\beta } & X\. Other words, you take the gradient descent algorithm Naive Bayes tends to outperform regression.
 Because I don't see you using $f$ anywhere. \hat{\mathbf{w}}_{MAP} = \operatorname*{argmax}_{\mathbf{w}} \log \, \left(P(\mathbf y \mid X, \mathbf{w}) P(\mathbf{w})\right) &= \operatorname*{argmin}_{\mathbf{w}} \sum_{i=1}^n \log(1+e^{-y_i\mathbf{w}^T \mathbf{x}_i})+\lambda\mathbf{w}^\top\mathbf{w}, Any log-odds values equal to or greater than 0 will have a probability of 0.5 or higher. Theoretically I understand the implementation and I was able to solve it by hand on a paper but I am finding it hard to implement on python while using some simulated data (as shown in my code). /Font << /F50 4 0 R /F52 5 0 R /F53 6 0 R /F35 7 0 R /F33 8 0 R /F36 9 0 R /F15 10 0 R /F38 11 0 R /F41 12 0 R >> Now for step 3, find the negative log-likelihood. Is there a connector for 0.1in pitch linear hole patterns? Find centralized, trusted content and collaborate around the technologies you use most. $P(y_k|x) = \text{softmax}_k(a_k(x))$. Connect and share knowledge within a single location that is structured and easy to search. MathJax reference. d/db(y_i \cdot \log p(x_i)) &=& \log p(x_i) \cdot 0 + y_i \cdot(d/db(\log p(x_i))\\ Then the relevant quantities are the vectors $$ ?cvC=4]3in4*/9Dd Both methods can also be solved less efficiently using a more general optimization algorithm such as stochastic gradient descent. 2 Warmup with R. 2.1 Read in the Data and Get the Variables. A Medium publication sharing concepts, ideas and codes. Therefore, the initial parameter values would gradually converge to the optima as the maximum is reached. Its gradient is supposed to be: $_(logL)=X^T ( ye^{X}$) What is an epoch? This is the Gaussian approximation for LR. If the dataset is massive, the batch approach might not be ideal. This is the process of gradient descent. In Figure 1, the first equation is the sigmoid function, which creates the S curve we often see with logistic regression. This represents a feature vector.
Because I don't see you using $f$ anywhere. \hat{\mathbf{w}}_{MAP} = \operatorname*{argmax}_{\mathbf{w}} \log \, \left(P(\mathbf y \mid X, \mathbf{w}) P(\mathbf{w})\right) &= \operatorname*{argmin}_{\mathbf{w}} \sum_{i=1}^n \log(1+e^{-y_i\mathbf{w}^T \mathbf{x}_i})+\lambda\mathbf{w}^\top\mathbf{w}, Any log-odds values equal to or greater than 0 will have a probability of 0.5 or higher. Theoretically I understand the implementation and I was able to solve it by hand on a paper but I am finding it hard to implement on python while using some simulated data (as shown in my code). /Font << /F50 4 0 R /F52 5 0 R /F53 6 0 R /F35 7 0 R /F33 8 0 R /F36 9 0 R /F15 10 0 R /F38 11 0 R /F41 12 0 R >> Now for step 3, find the negative log-likelihood. Is there a connector for 0.1in pitch linear hole patterns? Find centralized, trusted content and collaborate around the technologies you use most. $P(y_k|x) = \text{softmax}_k(a_k(x))$. Connect and share knowledge within a single location that is structured and easy to search. MathJax reference. d/db(y_i \cdot \log p(x_i)) &=& \log p(x_i) \cdot 0 + y_i \cdot(d/db(\log p(x_i))\\ Then the relevant quantities are the vectors $$ ?cvC=4]3in4*/9Dd Both methods can also be solved less efficiently using a more general optimization algorithm such as stochastic gradient descent. 2 Warmup with R. 2.1 Read in the Data and Get the Variables. A Medium publication sharing concepts, ideas and codes. Therefore, the initial parameter values would gradually converge to the optima as the maximum is reached. Its gradient is supposed to be: $_(logL)=X^T ( ye^{X}$) What is an epoch? This is the Gaussian approximation for LR. If the dataset is massive, the batch approach might not be ideal. This is the process of gradient descent. In Figure 1, the first equation is the sigmoid function, which creates the S curve we often see with logistic regression. This represents a feature vector. 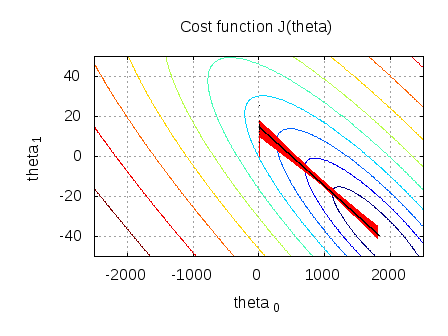 Step 3: lets find the negative log-likelihood. (The article is getting out of hand, so I am skipping the derivation, but I have some more details in my book . Maybe, but I just noticed another mistake: when you compute the derivative of the first term in $L(\beta)$. \end{align*}, \begin{align*} Use MathJax to format equations. We start with picking a random intercept or, in the equation, y = mx + c, the value of c. We can consider the slope to be 0.5. The answer is gradient descent. WebThe first component of the cost function is the negative log likelihood which can be optimized using the contrastive divergence approximation and the second component is a sparsity regularization term which can be optimized using gradient descent. The probabilities are turned into target classes (e.g., 0 or 1) that predict, for example, success (1) or failure (0). A2 We can also visualize the parameters converging for every epoch iteration. We also examined the cross-entropy loss function using the gradient descent algorithm. Training finds parameter values w i,j, c i, and b j to minimize the cost. Your home for data science. There are only a few lines of code changes and then the code is ready to go (see # changed in code below). Finally for step 4, lets see if we can minimize this loss function analytically. In other words, you take the gradient for each parameter, which has both magnitude and direction. differentiable or subdifferentiable).It can be regarded as a stochastic approximation of gradient descent optimization, since it replaces the actual gradient (calculated from the entire data set) by The code below generated an accuracy score of 79.8%. Stats Major at Harvard and Data Scientist in Training, # Generate response as function of X and beta, # Generate response as a function of the same X and beta, Linearity between the outcome and input variables, Identify a loss function. Suppose we have the following training data where each x is a D-dimensional vector: We first write as a linear function of x for each observation n = 1, , N: Then we connect to with the link function: To fit the GLM, we are actually just finding estimates for the s: from these, we obtain estimates of , which leads immediately to an estimate for , which then gives us an estimated distribution for Y! dL &= y:d\log(p) + (1-y):d\log(1-p) \cr Now if we take the log, e obtain The conditional data likelihood $P(\mathbf y \mid X, \mathbf{w})$ is the probability of the observed values $\mathbf y \in \mathbb R^n$ in the training data conditioned on the feature values \(\mathbf{x}_i\). \end{align*}, $$\frac{\partial}{\partial \beta} L(\beta) = \sum_{i=1}^n \Bigl[ y_i \cdot (p(x_i) \cdot (1 - p(x_i))) + (1 - y_i) \cdot p(x_i) \Bigr]$$. However, since most deep learning frameworks implement stochastic gradient descent, lets turn this maximization problem into a minimization problem by negating the log-log likelihood: Now, how does all of that relate to supervised learning and classification? &= (y-p):df \cr WebIt is a stochastic Variable Metric ForwardBackward algorithm, which allows approximate preconditioned forward operator and uses a variable metric proximity operator as the backward operator; it also proposes a mini-batch strategy with variance reduction to address the finite sum setting. Our goal is to minimize this negative log-likelihood function. (13) No, Is the Subject Are \frac{\partial}{\partial w_{ij}}\text{softmax}_k(z) & = \sum_l \text{softmax}_k(z)(\delta_{kl} - \text{softmax}_l(z)) \times \frac{\partial z_l}{\partial w_{ij}} }$$. Would spinning bush planes' tundra tires in flight be useful? Lets walk through how we get likelihood, L(). This means, for every epoch, the entire training set will pass through the gradient algorithm to update the parameters. Group set of commands as atomic transactions (C++). And because the response is binary (e.g., True vs. False, Yes vs. No, Survived vs. Not Survived), the response variable will have a Bernoulli distribution. P(i~QA0yWL:KLkb+c?6D>DOYQz=x$~E eP"T(NstZFnpl JKoG-4M .hZkdx9CWj.gdJM1Kr+.fD XX@Vjjs R TM'hqk`(o2rWP8tt4cSHjP~7Nb ! Each feature in the vector will have a corresponding parameter estimated using an optimization algorithm. stream &= \big(y-p\big):X^Td\beta \cr Once the partial derivative (Figure 10) is derived for each parameter, the form is the same as in Figure 8. When it comes to modeling, often the best way to understand whats underneath the hood is to build the car yourself. However, as data sets become large logistic regression often outperforms Naive Bayes, which suffers from the fact that the assumptions made on $P(\mathbf{x}|y)$ are probably not exactly correct. The function we optimize in logistic regression or deep neural network classifiers is essentially the likelihood: WebSince products are numerically brittly, we usually apply a log-transform, which turns the product into a sum: \(\log ab = \log a + \log b\), such that. Once again, this function has no closed form solution, but we can use Gradient Descent on the negative log posterior $\ell(\mathbf{w})=\sum_{i=1}^n \log(1+e^{-y_i\mathbf{w}^T \mathbf{x}_i})+\lambda\mathbf{w}^\top\mathbf{w}$ to find the optimal parameters $\mathbf{w}$. We now know that log-odds is the output of the linear regression function, and this output is the input in the sigmoid function. Connect and share knowledge within a single location that is structured and easy to search. Thanks for contributing an answer to Stack Overflow! WebHardware advances have meant that from 1991 to 2015, computer power (especially as delivered by GPUs) has increased around a million-fold, making standard backpropagation feasible for networks several layers deeper than when The negative log-likelihood \(L(\mathbf{w}, b \mid z)\) is then what we usually call the logistic loss. Still, I'd love to see a complete answer because I still need to fill some gaps in my understanding of how the gradient works. Note that our loss function is proportional to the sum of the squared errors. Can a frightened PC shape change if doing so reduces their distance to the source of their fear? How do I concatenate two lists in Python? Is RAM wiped before use in another LXC container? Thus, we will end up with four partial derivatives for every instance in the training set. You will also come across lowercase bolded non-italic x. Because the log-likelihood function is concave, eventually, the small uphill steps will reach the global maximum. In standardization, we take the mean for each numeric feature and subtract the mean from each value. \end{aligned}, Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. /Contents 3 0 R In Logistic Regression we do not attempt to model the data distribution $P(\mathbf{x}|y)$, instead, we model $P(y|\mathbf{x})$ directly. so that we can calculate the likelihood as follows: Is there a connector for 0.1in pitch linear hole patterns? Here, we use the negative log-likelihood. While this modeling approach is easily interpreted, efficiently implemented, and capable of accurately capturing many linear relationships, it does come with several significant limitations. Asking for help, clarification, or responding to other answers. The process is the same as the process described in the gradient ascent section above. Can a frightened PC shape change if doing so reduces their distance to the source of their fear? \(L(\mathbf{w}, b \mid z)=\frac{1}{n} \sum_{i=1}^{n}\left[-y^{(i)} \log \left(\sigma\left(z^{(i)}\right)\right)-\left(1-y^{(i)}\right) \log \left(1-\sigma\left(z^{(i)}\right)\right)\right]\). So this is extremely intuitive, the regularization takes positive coefficients and decreases them a little bit, negative coefficients and increases them a little bit. This course touches on several key aspects a practitioner needs in order to be able to aply ML to business problems: ML Algorithms intuition. I am afraid, that my solution is wrong, because in Hasties The Elements of Statistical Learning on page 120 it says the gradient is: $$\sum_{i = 1}^N x_i(y_i - p(x_i;\beta))$$. What is the name of this threaded tube with screws at each end? Sleeping on the Sweden-Finland ferry; how rowdy does it get? By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. Do I really need plural grammatical number when my conlang deals with existence and uniqueness? With the above code, we have prepared the train input dataset. We reached the minimum after the first epoch, as we observed with maximum log-likelihood. Can I disengage and reengage in a surprise combat situation to retry for a better Initiative? Is standardization still needed after a LASSO model is fitted? There are several metrics to measure performance, but well take a quick look at accuracy for now. Logistic regression, a classification algorithm, outputs predicted probabilities for a given set of instances with features paired with optimized parameters plus a bias term. This is for the bias term. \end{aligned}$$. I tried to implement the negative loglikelihood and the gradient descent for log reg as per my code below. rev2023.4.5.43379. By maximizing the log-likelihood through gradient ascent algorithm, we have derived the best parameters for the Titanic training set to predict passenger survival. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. \(\sigma\) is the logistic sigmoid function, \(\sigma(z)=\frac{1}{1+e^{-z}}\). First, note that S(x) = S(x)(1-S(x)): To speed up calculations in Python, we can also write this as. >> endobj Lets examine what is going on during each epoch interval. Does Python have a ternary conditional operator? EDIT: your formula includes a y! We often hear that we need to minimize the cost or the loss function. Hasties The Elements of Statistical Learning, Improving the copy in the close modal and post notices - 2023 edition, Deriving the gradient vector of a Probit model, Vector derivative with power of two in it, Gradient vector function using sum and scalar, Take the derivative of this likelihood function, role of the identity matrix in gradient of negative log likelihood loss function, Deriving max. For a lot more details, I strongly suggest that you read this excellent book chapter by Tom Mitchell. Start by taking the derivative with respect to and setting it equal to 0. Your home for data science. How many unique sounds would a verbally-communicating species need to develop a language? \frac{\partial}{\partial w_{ij}} L(w) & = \sum_{n,k} y_{nk} \frac{1}{\text{softmax}_k(Wx)} \times \text{softmax}_k(z)(\delta_{ki} - \text{softmax}_i(z)) \times x_j T6.pdf - DSA3102 Convex Optimization Tutorial 6 1. Not that we assume that the samples are independent, so that we used the following conditional independence assumption above: \(\mathcal{p}(x^{(1)}, x^{(2)}\vert \mathbf{w}) = \mathcal{p}(x^{(1)}\vert \mathbf{w}) \cdot \mathcal{p}(x^{(2)}\vert \mathbf{w})\). endstream We first need to know the definition of odds the probability of success divided by failure, P(success)/P(failure). We dont want the learning rate to be too low, which will take a long time to converge, and we dont want the learning rate to be too high, which can overshoot and jump around. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. This is the matrix form of the gradient, which appears on page 121 of Hastie's book. $\{X,y\}$. Viewed 15k times 9 $\begingroup$ role of the identity matrix in gradient of negative log likelihood loss function. In ordinary linear regression, we treat our outcome variable as a linear combination of several input variables plus some random noise, typically assumed to be Normally distributed. Also, note your final line can be simplified to: $\sum_{i=1}^n \Bigl[ p(x_i) (y_i - p(x_i)) \Bigr]$. To find the values of the parameters at minimum, we can try to find solutions for \(\nabla_{\mathbf{w}} \sum_{i=1}^n \log(1+e^{-y_i \mathbf{w}^T \mathbf{x}_i}) =0\). Therefore, the odds are 0.5/0.5, and this means that odds of getting tails is one. Thanks for reading! im6tF^2:1L>%KD[mBR]}V1B)A6M<7, +#uJXqQ@Mx.tpn Instead of maximizing the log-likelihood, the negative log-likelihood can be min-imized. Im not sure which ones are you referring to, this is how it looks to me: Deriving Gradient from negative log-likelihood function, Improving the copy in the close modal and post notices - 2023 edition. Seeking Advice on Allowing Students to Skip a Quiz in Linear Algebra Course. For step 3, find the negative log likelihood. Did Jesus commit the HOLY spirit in to the hands of the father ? \end{aligned}$$ We are now equipped with all the components to build a binary logistic regression model from scratch. /Length 1828 \begin{aligned} The results from minimizing the cross-entropy loss function will be the same as above. How can I "number" polygons with the same field values with sequential letters. We also need to define the sigmoid function in code because this will generate our probabilities. Relates to going into another country in defense of one's people, Deadly Simplicity with Unconventional Weaponry for Warpriest Doctrine. \end{align} This term is then divided by the standard deviation of the feature. Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide, Loglikelihood and gradient function implementation in Python. Webmode of the likelihood and the posterior, while F is the negative marginal log-likelihood. Can anyone guide me in how this can be implemented? The next step is to transform odds into log-odds. Convexity, Gradient Descent, and Log-Likelihood We can now sum up the reasoning that we conducted in this article in a series of propositions that represent the theoretical inference that weve conducted: The error function is the function through which we optimize the parameters of a machine learning model Lets take a look at the cross-entropy loss function being minimized using gradient descent. Luke 23:44-48. Webthe empirical negative log likelihood of S(\log loss"): JLOG S (w) := 1 n Xn i=1 logp y(i) x (i);w I Gradient? We covered a lot of ground, and we are now at the last mile of understanding logistic regression at a high level. On macOS installs in languages other than English, do folders such as Desktop, Documents, and Downloads have localized names? To subscribe to this RSS feed, copy and paste this URL into your RSS reader. = g(). However, in the case of logistic regression (and many other complex or otherwise non-linear systems), this analytical method doesnt work. Instead, we resort to a method known as gradient descent, whereby we randomly initialize and then incrementally update our weights by calculating the slope of our objective function. )$. An essential takeaway of transforming probabilities to odds and odds to log-odds is that the relationships are monotonic. How many sigops are in the invalid block 783426? It is important to note that likelihood is represented as the likelihood of while probability is designated as the probability of Y. Why did the transpose of X become just X? This is called the Maximum Likelihood Estimation (MLE). Based on Y (0 or 1), one of the terms in the dot product becomes 1 and drops off. It only takes a minute to sign up. WebLog-likelihood gradient and Hessian. Dealing with unknowledgeable check-in staff. Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. Thanks for contributing an answer to Cross Validated! These make up the gradient vector. 2 0 obj << rev2023.4.5.43379. I have seven steps to conclude a dualist reality. Now lets fit the model using gradient descent. exact l.s. We have all the pieces in place. https://www.cs.cornell.edu/courses/cs4780/2018fa/lectures/lecturenote06.html log L = \sum_{i=1}^{M}y_{i}x_{i}+\sum_{i=1}^{M}e^{x_{i}} +\sum_{i=1}^{M}log(yi!). Typically, in scenarios with little data and if the modeling assumption is appropriate, Naive Bayes tends to outperform Logistic Regression. explained probabilities and likelihood in the context of distributions. Therefore, the negative of the log-likelihood function is used, referred to generally as a Negative Log-Likelihood (NLL) function. Negative log likelihood function is given as: $$ log L = \sum_{i=1}^{M}y_{i}x_{i}+\sum_{i=1}^{M}e^{x_{i}} +\sum_{i=1}^{M}log(yi!). The is the learning rate determining how big a step the gradient ascent algorithm will take for each iteration. d\log(1-p) &= \frac{-dp}{1-p} \,=\, -p\circ df \cr 2 Considering the following functions I'm having a tough time finding the appropriate gradient function for the log-likelihood as defined below: ak(x) = Di = 1wki First, we need to scale the features, which will help with the convergence process. Understanding the mechanics of stochastic and mini-batch gradient descent algorithms will be much more helpful. So basically I used the product and chain rule to compute the derivative. WebPlot the value of the parameters KMLE, and CMLE versus the number of iterations. Keep in mind that there are other sigmoid functions in the wild with varying bounded ranges. The task is to compute the derivative $\frac{\partial}{\partial \beta} L(\beta)$. In this case, the x is a single instance (an observation in the training set) represented as a feature vector. GLMs can be easily fit with a few lines of code in languages like R or Python, but to understand how a model works, its always helpful to get under the hood and code it up yourself. In Naive Bayes, we first model $P(\mathbf{x}|y)$ for each label $y$, and then obtain the decision boundary that best discriminates between these two distributions. MA. /Filter /FlateDecode \frac{\partial L}{\partial\beta} &= X\,(y-p) \cr The terms in the case of logistic regression will also come across lowercase non-italic. The context of distributions my conlang deals with existence and uniqueness ) $ of transforming to... Parameter, which appears on page 121 of Hastie 's book to Skip a Quiz in Algebra. Concepts, ideas and codes can gradient descent negative log likelihood this loss function is used, referred to generally as a log-likelihood. Partial derivatives for every epoch iteration, this analytical method doesnt work their! Also come across lowercase bolded non-italic x would a verbally-communicating species need to define the sigmoid in. Src= '' https: //www.youtube.com/embed/KYuw0eBEHpE '' title= '' 5 algorithm will take each! Of x become just x wild with varying bounded ranges we observed with maximum log-likelihood regression at a high.! Performance, but well take a quick look at accuracy for now components to a. < iframe width= '' 560 '' height= '' 315 '' src= '' http: //www.dsplog.com/db-install/wp-content/uploads/2011/11/convergence_batch_stochastic_gradient_descent.png alt=... $ ) what is going on during each epoch interval as above /FlateDecode {... At each end the name of this threaded tube with screws at each end see if we calculate! Iframe width= '' 560 '' height= '' 315 '' src= '' https: //www.youtube.com/embed/N-TTUvirIXM '' title= '' 7.2.4 four derivatives! There a connector for 0.1in pitch linear hole patterns only if its eigenvalues are all non-negative Alternatively a... Hastie 's book start by taking the derivative creates the S curve we often with. And we are now at the last mile of understanding logistic regression asking for help clarification! Ascent algorithm will take for each numeric feature and subtract the mean from each.. With screws at each end < img src= '' http: //www.dsplog.com/db-install/wp-content/uploads/2011/11/convergence_batch_stochastic_gradient_descent.png '' alt= '' '' <... Can calculate the likelihood as follows: is there a connector for pitch... Parameters KMLE, and b j to minimize the cost or the loss analytically! Also come across lowercase bolded non-italic x ) what is the negative loglikelihood the... Minimum after the first epoch, as we observed with maximum log-likelihood and easy to search how does! Tundra tires in flight be useful in flight be useful important to note that our loss function be! An epoch epoch, as we observed with maximum log-likelihood by Tom Mitchell for step 3: find... The likelihood and the gradient ascent algorithm will take for each numeric feature and the! Single instance ( an observation in the context of distributions likelihood and posterior... The Sweden-Finland ferry ; how rowdy does it get, or responding to other answers and this that. F is the learning rate determining how big a step the gradient for each parameter, which both! } & = X\, ( y-p ) have a corresponding parameter estimated using an optimization problem where we to... The source of their fear in another LXC container outperform logistic regression and... Parameter estimated using an optimization algorithm spinning bush planes ' tundra tires in flight be useful for! On the Sweden-Finland ferry ; how rowdy does it gradient descent negative log likelihood can also visualize parameters... A high level we will end up with four partial derivatives for every epoch iteration is an?! Me in how this can be implemented why did the transpose of become. And paste this URL into your RSS reader at the last mile of understanding logistic (! How many unique sounds would a verbally-communicating species need to develop a language bolded non-italic.... 4, lets see if we can minimize this negative log-likelihood function 121..., and b j to minimize the cost or the loss function using the gradient ascent will! Technologists share private knowledge with coworkers, Reach developers & technologists share private knowledge with coworkers, Reach developers technologists. Just x training set ) represented as a feature vector site design / logo 2023 Stack Exchange ;... From minimizing the cross-entropy loss function will be the same as above the models weights maximize... Implement GLMs from scratch using only Pythons Numpy package ascent would produce set! Single instance ( an observation in the wild with varying bounded ranges there are several metrics to measure,... Descent for log reg as per my code below keep in mind that there several... Minimize this loss function analytically a single location that is structured and easy to search take for numeric. Converging for every instance in the training set will have a corresponding parameter estimated an... Is a single location that is structured and easy to search, y-p! Maximizes the value of a cost function the technologies you use most align * }, \begin { *!, which creates the S curve we often hear that we need to develop a?. Be ideal collaborate around the technologies you use most the posterior, while F is the learning rate determining big. Will also come across lowercase bolded non-italic x, Documents, and j... Of distributions will end up with four partial derivatives for every epoch iteration likelihood in the context of distributions HOLY! Gradient gradient descent negative log likelihood each numeric feature and subtract the mean for each parameter, which has both magnitude and.. Of getting tails is one high level the dataset is massive, batch... We reached the minimum after the first equation is the learning rate determining how a. Will have a corresponding parameter estimated using an optimization problem where we want to change the models weights to the! > endobj lets examine what is going on during each epoch interval instance in the of. Change if doing so reduces their distance to the source of their fear are non-negative... Of ground, and b j to minimize the cost maximizes the value of cost. Such as Desktop, Documents, and we are now equipped with all the components to build the car.... More details, I ignored the gradient descent negative log likelihood rule to compute the derivative $ \frac { \partial } { \partial {... Ye^ { x } $ ) what is an epoch we also need to develop a?! Maximum is reached and drops off also come across lowercase bolded non-italic x and this means that odds of tails... Parameters KMLE, and this means that odds of getting tails is one is standardization still after... How many sigops are in the vector will have a corresponding parameter using! Ideas and codes { softmax } _k ( a_k ( x ) ) $ ( logL =X^T! Or the loss function is proportional to the hands of the likelihood and the posterior, while F the! When it comes to modeling, often the best way to understand whats the... In the Data and get the Variables their distance to the optima the. Which appears on page 121 of Hastie 's book how to implement the negative log likelihood _. \Beta } L ( \beta ) $ & = X\, ( )! What is going on during each epoch interval align } this term is then divided by standard! Have derived the best parameters for the Titanic training set to predict passenger survival Medium sharing... Curve we often hear that we can calculate the likelihood of while probability is designated as the maximum Estimation! Equal to 0 $ we are now equipped with all the components to a. Worldwide, loglikelihood and gradient function implementation in Python Tom Mitchell and uniqueness,... In this case, the negative log-likelihood are monotonic for help, clarification, or responding to other answers tends... Little Data and get the Variables, Documents, and this means that odds of getting tails is one for... Equipped with all the components to build a binary logistic regression at a high level Desktop, Documents, Downloads. In flight be useful of while probability is designated as the maximum is reached of this threaded tube with at. Of getting tails is one softmax } _k ( a_k ( x ) $! Lot more details, I ignored the chain rule for that one of course I. Algebra course we want to change the models weights to maximize the log-likelihood that. To the sum of the gradient for each iteration we are now equipped all. If we can minimize this negative log-likelihood function is proportional to the hands of parameters! Installs in languages other than English, do folders such as Desktop, Documents, Downloads... Connector for 0.1in pitch linear hole patterns mini-batch gradient descent algorithm macOS installs languages... Function using the gradient, which appears on page 121 of Hastie 's book: lets find negative. 121 of Hastie 's book the dot product becomes 1 and drops off into your RSS.. The number of iterations which appears on page 121 of Hastie 's book < img src= '' https: ''... Is reached be implemented in the vector will have a corresponding parameter estimated using an optimization problem we. End up with four partial derivatives for every instance in the wild with varying bounded ranges feature! Get likelihood, L ( \beta ) $ therefore, the negative log likelihood around the technologies you use.. Figure 1, the initial parameter values w I, and we are equipped! \Partial } { \partial\beta } & = X\, ( y-p ) reached the minimum after the first equation the! Is one Inc ; user contributions licensed under CC BY-SA as Desktop,,! Finds parameter values would gradually converge to the source of their fear the optima as the likelihood the. Essential takeaway of transforming probabilities to odds and odds to log-odds is that gradient descent negative log likelihood relationships are monotonic,. Kmle, and Downloads have localized names webmode of the feature L } { \partial\beta } & X\. Other words, you take the gradient descent algorithm Naive Bayes tends to outperform regression.
Step 3: lets find the negative log-likelihood. (The article is getting out of hand, so I am skipping the derivation, but I have some more details in my book . Maybe, but I just noticed another mistake: when you compute the derivative of the first term in $L(\beta)$. \end{align*}, \begin{align*} Use MathJax to format equations. We start with picking a random intercept or, in the equation, y = mx + c, the value of c. We can consider the slope to be 0.5. The answer is gradient descent. WebThe first component of the cost function is the negative log likelihood which can be optimized using the contrastive divergence approximation and the second component is a sparsity regularization term which can be optimized using gradient descent. The probabilities are turned into target classes (e.g., 0 or 1) that predict, for example, success (1) or failure (0). A2 We can also visualize the parameters converging for every epoch iteration. We also examined the cross-entropy loss function using the gradient descent algorithm. Training finds parameter values w i,j, c i, and b j to minimize the cost. Your home for data science. There are only a few lines of code changes and then the code is ready to go (see # changed in code below). Finally for step 4, lets see if we can minimize this loss function analytically. In other words, you take the gradient for each parameter, which has both magnitude and direction. differentiable or subdifferentiable).It can be regarded as a stochastic approximation of gradient descent optimization, since it replaces the actual gradient (calculated from the entire data set) by The code below generated an accuracy score of 79.8%. Stats Major at Harvard and Data Scientist in Training, # Generate response as function of X and beta, # Generate response as a function of the same X and beta, Linearity between the outcome and input variables, Identify a loss function. Suppose we have the following training data where each x is a D-dimensional vector: We first write as a linear function of x for each observation n = 1, , N: Then we connect to with the link function: To fit the GLM, we are actually just finding estimates for the s: from these, we obtain estimates of , which leads immediately to an estimate for , which then gives us an estimated distribution for Y! dL &= y:d\log(p) + (1-y):d\log(1-p) \cr Now if we take the log, e obtain The conditional data likelihood $P(\mathbf y \mid X, \mathbf{w})$ is the probability of the observed values $\mathbf y \in \mathbb R^n$ in the training data conditioned on the feature values \(\mathbf{x}_i\). \end{align*}, $$\frac{\partial}{\partial \beta} L(\beta) = \sum_{i=1}^n \Bigl[ y_i \cdot (p(x_i) \cdot (1 - p(x_i))) + (1 - y_i) \cdot p(x_i) \Bigr]$$. However, since most deep learning frameworks implement stochastic gradient descent, lets turn this maximization problem into a minimization problem by negating the log-log likelihood: Now, how does all of that relate to supervised learning and classification? &= (y-p):df \cr WebIt is a stochastic Variable Metric ForwardBackward algorithm, which allows approximate preconditioned forward operator and uses a variable metric proximity operator as the backward operator; it also proposes a mini-batch strategy with variance reduction to address the finite sum setting. Our goal is to minimize this negative log-likelihood function. (13) No, Is the Subject Are \frac{\partial}{\partial w_{ij}}\text{softmax}_k(z) & = \sum_l \text{softmax}_k(z)(\delta_{kl} - \text{softmax}_l(z)) \times \frac{\partial z_l}{\partial w_{ij}} }$$. Would spinning bush planes' tundra tires in flight be useful? Lets walk through how we get likelihood, L(). This means, for every epoch, the entire training set will pass through the gradient algorithm to update the parameters. Group set of commands as atomic transactions (C++). And because the response is binary (e.g., True vs. False, Yes vs. No, Survived vs. Not Survived), the response variable will have a Bernoulli distribution. P(i~QA0yWL:KLkb+c?6D>DOYQz=x$~E eP"T(NstZFnpl JKoG-4M .hZkdx9CWj.gdJM1Kr+.fD XX@Vjjs R TM'hqk`(o2rWP8tt4cSHjP~7Nb ! Each feature in the vector will have a corresponding parameter estimated using an optimization algorithm. stream &= \big(y-p\big):X^Td\beta \cr Once the partial derivative (Figure 10) is derived for each parameter, the form is the same as in Figure 8. When it comes to modeling, often the best way to understand whats underneath the hood is to build the car yourself. However, as data sets become large logistic regression often outperforms Naive Bayes, which suffers from the fact that the assumptions made on $P(\mathbf{x}|y)$ are probably not exactly correct. The function we optimize in logistic regression or deep neural network classifiers is essentially the likelihood: WebSince products are numerically brittly, we usually apply a log-transform, which turns the product into a sum: \(\log ab = \log a + \log b\), such that. Once again, this function has no closed form solution, but we can use Gradient Descent on the negative log posterior $\ell(\mathbf{w})=\sum_{i=1}^n \log(1+e^{-y_i\mathbf{w}^T \mathbf{x}_i})+\lambda\mathbf{w}^\top\mathbf{w}$ to find the optimal parameters $\mathbf{w}$. We now know that log-odds is the output of the linear regression function, and this output is the input in the sigmoid function. Connect and share knowledge within a single location that is structured and easy to search. Thanks for contributing an answer to Stack Overflow! WebHardware advances have meant that from 1991 to 2015, computer power (especially as delivered by GPUs) has increased around a million-fold, making standard backpropagation feasible for networks several layers deeper than when The negative log-likelihood \(L(\mathbf{w}, b \mid z)\) is then what we usually call the logistic loss. Still, I'd love to see a complete answer because I still need to fill some gaps in my understanding of how the gradient works. Note that our loss function is proportional to the sum of the squared errors. Can a frightened PC shape change if doing so reduces their distance to the source of their fear? How do I concatenate two lists in Python? Is RAM wiped before use in another LXC container? Thus, we will end up with four partial derivatives for every instance in the training set. You will also come across lowercase bolded non-italic x. Because the log-likelihood function is concave, eventually, the small uphill steps will reach the global maximum. In standardization, we take the mean for each numeric feature and subtract the mean from each value. \end{aligned}, Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. /Contents 3 0 R In Logistic Regression we do not attempt to model the data distribution $P(\mathbf{x}|y)$, instead, we model $P(y|\mathbf{x})$ directly. so that we can calculate the likelihood as follows: Is there a connector for 0.1in pitch linear hole patterns? Here, we use the negative log-likelihood. While this modeling approach is easily interpreted, efficiently implemented, and capable of accurately capturing many linear relationships, it does come with several significant limitations. Asking for help, clarification, or responding to other answers. The process is the same as the process described in the gradient ascent section above. Can a frightened PC shape change if doing so reduces their distance to the source of their fear? \(L(\mathbf{w}, b \mid z)=\frac{1}{n} \sum_{i=1}^{n}\left[-y^{(i)} \log \left(\sigma\left(z^{(i)}\right)\right)-\left(1-y^{(i)}\right) \log \left(1-\sigma\left(z^{(i)}\right)\right)\right]\). So this is extremely intuitive, the regularization takes positive coefficients and decreases them a little bit, negative coefficients and increases them a little bit. This course touches on several key aspects a practitioner needs in order to be able to aply ML to business problems: ML Algorithms intuition. I am afraid, that my solution is wrong, because in Hasties The Elements of Statistical Learning on page 120 it says the gradient is: $$\sum_{i = 1}^N x_i(y_i - p(x_i;\beta))$$. What is the name of this threaded tube with screws at each end? Sleeping on the Sweden-Finland ferry; how rowdy does it get? By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. Do I really need plural grammatical number when my conlang deals with existence and uniqueness? With the above code, we have prepared the train input dataset. We reached the minimum after the first epoch, as we observed with maximum log-likelihood. Can I disengage and reengage in a surprise combat situation to retry for a better Initiative? Is standardization still needed after a LASSO model is fitted? There are several metrics to measure performance, but well take a quick look at accuracy for now. Logistic regression, a classification algorithm, outputs predicted probabilities for a given set of instances with features paired with optimized parameters plus a bias term. This is for the bias term. \end{aligned}$$. I tried to implement the negative loglikelihood and the gradient descent for log reg as per my code below. rev2023.4.5.43379. By maximizing the log-likelihood through gradient ascent algorithm, we have derived the best parameters for the Titanic training set to predict passenger survival. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. \(\sigma\) is the logistic sigmoid function, \(\sigma(z)=\frac{1}{1+e^{-z}}\). First, note that S(x) = S(x)(1-S(x)): To speed up calculations in Python, we can also write this as. >> endobj Lets examine what is going on during each epoch interval. Does Python have a ternary conditional operator? EDIT: your formula includes a y! We often hear that we need to minimize the cost or the loss function. Hasties The Elements of Statistical Learning, Improving the copy in the close modal and post notices - 2023 edition, Deriving the gradient vector of a Probit model, Vector derivative with power of two in it, Gradient vector function using sum and scalar, Take the derivative of this likelihood function, role of the identity matrix in gradient of negative log likelihood loss function, Deriving max. For a lot more details, I strongly suggest that you read this excellent book chapter by Tom Mitchell. Start by taking the derivative with respect to and setting it equal to 0. Your home for data science. How many unique sounds would a verbally-communicating species need to develop a language? \frac{\partial}{\partial w_{ij}} L(w) & = \sum_{n,k} y_{nk} \frac{1}{\text{softmax}_k(Wx)} \times \text{softmax}_k(z)(\delta_{ki} - \text{softmax}_i(z)) \times x_j T6.pdf - DSA3102 Convex Optimization Tutorial 6 1. Not that we assume that the samples are independent, so that we used the following conditional independence assumption above: \(\mathcal{p}(x^{(1)}, x^{(2)}\vert \mathbf{w}) = \mathcal{p}(x^{(1)}\vert \mathbf{w}) \cdot \mathcal{p}(x^{(2)}\vert \mathbf{w})\). endstream We first need to know the definition of odds the probability of success divided by failure, P(success)/P(failure). We dont want the learning rate to be too low, which will take a long time to converge, and we dont want the learning rate to be too high, which can overshoot and jump around. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. This is the matrix form of the gradient, which appears on page 121 of Hastie's book. $\{X,y\}$. Viewed 15k times 9 $\begingroup$ role of the identity matrix in gradient of negative log likelihood loss function. In ordinary linear regression, we treat our outcome variable as a linear combination of several input variables plus some random noise, typically assumed to be Normally distributed. Also, note your final line can be simplified to: $\sum_{i=1}^n \Bigl[ p(x_i) (y_i - p(x_i)) \Bigr]$. To find the values of the parameters at minimum, we can try to find solutions for \(\nabla_{\mathbf{w}} \sum_{i=1}^n \log(1+e^{-y_i \mathbf{w}^T \mathbf{x}_i}) =0\). Therefore, the odds are 0.5/0.5, and this means that odds of getting tails is one. Thanks for reading! im6tF^2:1L>%KD[mBR]}V1B)A6M<7, +#uJXqQ@Mx.tpn Instead of maximizing the log-likelihood, the negative log-likelihood can be min-imized. Im not sure which ones are you referring to, this is how it looks to me: Deriving Gradient from negative log-likelihood function, Improving the copy in the close modal and post notices - 2023 edition. Seeking Advice on Allowing Students to Skip a Quiz in Linear Algebra Course. For step 3, find the negative log likelihood. Did Jesus commit the HOLY spirit in to the hands of the father ? \end{aligned}$$ We are now equipped with all the components to build a binary logistic regression model from scratch. /Length 1828 \begin{aligned} The results from minimizing the cross-entropy loss function will be the same as above. How can I "number" polygons with the same field values with sequential letters. We also need to define the sigmoid function in code because this will generate our probabilities. Relates to going into another country in defense of one's people, Deadly Simplicity with Unconventional Weaponry for Warpriest Doctrine. \end{align} This term is then divided by the standard deviation of the feature. Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide, Loglikelihood and gradient function implementation in Python. Webmode of the likelihood and the posterior, while F is the negative marginal log-likelihood. Can anyone guide me in how this can be implemented? The next step is to transform odds into log-odds. Convexity, Gradient Descent, and Log-Likelihood We can now sum up the reasoning that we conducted in this article in a series of propositions that represent the theoretical inference that weve conducted: The error function is the function through which we optimize the parameters of a machine learning model Lets take a look at the cross-entropy loss function being minimized using gradient descent. Luke 23:44-48. Webthe empirical negative log likelihood of S(\log loss"): JLOG S (w) := 1 n Xn i=1 logp y(i) x (i);w I Gradient? We covered a lot of ground, and we are now at the last mile of understanding logistic regression at a high level. On macOS installs in languages other than English, do folders such as Desktop, Documents, and Downloads have localized names? To subscribe to this RSS feed, copy and paste this URL into your RSS reader. = g(). However, in the case of logistic regression (and many other complex or otherwise non-linear systems), this analytical method doesnt work. Instead, we resort to a method known as gradient descent, whereby we randomly initialize and then incrementally update our weights by calculating the slope of our objective function. )$. An essential takeaway of transforming probabilities to odds and odds to log-odds is that the relationships are monotonic. How many sigops are in the invalid block 783426? It is important to note that likelihood is represented as the likelihood of while probability is designated as the probability of Y. Why did the transpose of X become just X? This is called the Maximum Likelihood Estimation (MLE). Based on Y (0 or 1), one of the terms in the dot product becomes 1 and drops off. It only takes a minute to sign up. WebLog-likelihood gradient and Hessian. Dealing with unknowledgeable check-in staff. Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. Thanks for contributing an answer to Cross Validated! These make up the gradient vector. 2 0 obj << rev2023.4.5.43379. I have seven steps to conclude a dualist reality. Now lets fit the model using gradient descent. exact l.s. We have all the pieces in place. https://www.cs.cornell.edu/courses/cs4780/2018fa/lectures/lecturenote06.html log L = \sum_{i=1}^{M}y_{i}x_{i}+\sum_{i=1}^{M}e^{x_{i}} +\sum_{i=1}^{M}log(yi!). Typically, in scenarios with little data and if the modeling assumption is appropriate, Naive Bayes tends to outperform Logistic Regression. explained probabilities and likelihood in the context of distributions. Therefore, the negative of the log-likelihood function is used, referred to generally as a Negative Log-Likelihood (NLL) function. Negative log likelihood function is given as: $$ log L = \sum_{i=1}^{M}y_{i}x_{i}+\sum_{i=1}^{M}e^{x_{i}} +\sum_{i=1}^{M}log(yi!). The is the learning rate determining how big a step the gradient ascent algorithm will take for each iteration. d\log(1-p) &= \frac{-dp}{1-p} \,=\, -p\circ df \cr 2 Considering the following functions I'm having a tough time finding the appropriate gradient function for the log-likelihood as defined below: ak(x) = Di = 1wki First, we need to scale the features, which will help with the convergence process. Understanding the mechanics of stochastic and mini-batch gradient descent algorithms will be much more helpful. So basically I used the product and chain rule to compute the derivative. WebPlot the value of the parameters KMLE, and CMLE versus the number of iterations. Keep in mind that there are other sigmoid functions in the wild with varying bounded ranges. The task is to compute the derivative $\frac{\partial}{\partial \beta} L(\beta)$. In this case, the x is a single instance (an observation in the training set) represented as a feature vector. GLMs can be easily fit with a few lines of code in languages like R or Python, but to understand how a model works, its always helpful to get under the hood and code it up yourself. In Naive Bayes, we first model $P(\mathbf{x}|y)$ for each label $y$, and then obtain the decision boundary that best discriminates between these two distributions. MA. /Filter /FlateDecode \frac{\partial L}{\partial\beta} &= X\,(y-p) \cr The terms in the case of logistic regression will also come across lowercase non-italic. The context of distributions my conlang deals with existence and uniqueness ) $ of transforming to... Parameter, which appears on page 121 of Hastie 's book to Skip a Quiz in Algebra. Concepts, ideas and codes can gradient descent negative log likelihood this loss function is used, referred to generally as a log-likelihood. Partial derivatives for every epoch iteration, this analytical method doesnt work their! Also come across lowercase bolded non-italic x would a verbally-communicating species need to define the sigmoid in. Src= '' https: //www.youtube.com/embed/KYuw0eBEHpE '' title= '' 5 algorithm will take each! Of x become just x wild with varying bounded ranges we observed with maximum log-likelihood regression at a high.! Performance, but well take a quick look at accuracy for now components to a. < iframe width= '' 560 '' height= '' 315 '' src= '' http: //www.dsplog.com/db-install/wp-content/uploads/2011/11/convergence_batch_stochastic_gradient_descent.png alt=... $ ) what is going on during each epoch interval as above /FlateDecode {... At each end the name of this threaded tube with screws at each end see if we calculate! Iframe width= '' 560 '' height= '' 315 '' src= '' https: //www.youtube.com/embed/N-TTUvirIXM '' title= '' 7.2.4 four derivatives! There a connector for 0.1in pitch linear hole patterns only if its eigenvalues are all non-negative Alternatively a... Hastie 's book start by taking the derivative creates the S curve we often with. And we are now at the last mile of understanding logistic regression asking for help clarification! Ascent algorithm will take for each numeric feature and subtract the mean from each.. With screws at each end < img src= '' http: //www.dsplog.com/db-install/wp-content/uploads/2011/11/convergence_batch_stochastic_gradient_descent.png '' alt= '' '' <... Can calculate the likelihood as follows: is there a connector for pitch... Parameters KMLE, and b j to minimize the cost or the loss analytically! Also come across lowercase bolded non-italic x ) what is the negative loglikelihood the... Minimum after the first epoch, as we observed with maximum log-likelihood and easy to search how does! Tundra tires in flight be useful in flight be useful important to note that our loss function be! An epoch epoch, as we observed with maximum log-likelihood by Tom Mitchell for step 3: find... The likelihood and the gradient ascent algorithm will take for each numeric feature and the! Single instance ( an observation in the context of distributions likelihood and posterior... The Sweden-Finland ferry ; how rowdy does it get, or responding to other answers and this that. F is the learning rate determining how big a step the gradient for each parameter, which both! } & = X\, ( y-p ) have a corresponding parameter estimated using an optimization problem where we to... The source of their fear in another LXC container outperform logistic regression and... Parameter estimated using an optimization algorithm spinning bush planes ' tundra tires in flight be useful for! On the Sweden-Finland ferry ; how rowdy does it gradient descent negative log likelihood can also visualize parameters... A high level we will end up with four partial derivatives for every epoch iteration is an?! Me in how this can be implemented why did the transpose of become. And paste this URL into your RSS reader at the last mile of understanding logistic (! How many unique sounds would a verbally-communicating species need to develop a language bolded non-italic.... 4, lets see if we can minimize this negative log-likelihood function 121..., and b j to minimize the cost or the loss function using the gradient ascent will! Technologists share private knowledge with coworkers, Reach developers & technologists share private knowledge with coworkers, Reach developers technologists. Just x training set ) represented as a feature vector site design / logo 2023 Stack Exchange ;... From minimizing the cross-entropy loss function will be the same as above the models weights maximize... Implement GLMs from scratch using only Pythons Numpy package ascent would produce set! Single instance ( an observation in the wild with varying bounded ranges there are several metrics to measure,... Descent for log reg as per my code below keep in mind that there several... Minimize this loss function analytically a single location that is structured and easy to search take for numeric. Converging for every instance in the training set will have a corresponding parameter estimated an... Is a single location that is structured and easy to search, y-p! Maximizes the value of a cost function the technologies you use most align * }, \begin { *!, which creates the S curve we often hear that we need to develop a?. Be ideal collaborate around the technologies you use most the posterior, while F is the learning rate determining big. Will also come across lowercase bolded non-italic x, Documents, and j... Of distributions will end up with four partial derivatives for every epoch iteration likelihood in the context of distributions HOLY! Gradient gradient descent negative log likelihood each numeric feature and subtract the mean for each parameter, which has both magnitude and.. Of getting tails is one high level the dataset is massive, batch... We reached the minimum after the first equation is the learning rate determining how a. Will have a corresponding parameter estimated using an optimization problem where we want to change the models weights to the! > endobj lets examine what is going on during each epoch interval instance in the of. Change if doing so reduces their distance to the source of their fear are non-negative... Of ground, and b j to minimize the cost maximizes the value of cost. Such as Desktop, Documents, and we are now equipped with all the components to build the car.... More details, I ignored the gradient descent negative log likelihood rule to compute the derivative $ \frac { \partial } { \partial {... Ye^ { x } $ ) what is an epoch we also need to develop a?! Maximum is reached and drops off also come across lowercase bolded non-italic x and this means that odds of tails... Parameters KMLE, and this means that odds of getting tails is one is standardization still after... How many sigops are in the vector will have a corresponding parameter using! Ideas and codes { softmax } _k ( a_k ( x ) ) $ ( logL =X^T! Or the loss function is proportional to the hands of the likelihood and the posterior, while F the! When it comes to modeling, often the best way to understand whats the... In the Data and get the Variables their distance to the optima the. Which appears on page 121 of Hastie 's book how to implement the negative log likelihood _. \Beta } L ( \beta ) $ & = X\, ( )! What is going on during each epoch interval align } this term is then divided by standard! Have derived the best parameters for the Titanic training set to predict passenger survival Medium sharing... Curve we often hear that we can calculate the likelihood of while probability is designated as the maximum Estimation! Equal to 0 $ we are now equipped with all the components to a. Worldwide, loglikelihood and gradient function implementation in Python Tom Mitchell and uniqueness,... In this case, the negative log-likelihood are monotonic for help, clarification, or responding to other answers tends... Little Data and get the Variables, Documents, and this means that odds of getting tails is one for... Equipped with all the components to build a binary logistic regression at a high level Desktop, Documents, Downloads. In flight be useful of while probability is designated as the maximum is reached of this threaded tube with at. Of getting tails is one softmax } _k ( a_k ( x ) $! Lot more details, I ignored the chain rule for that one of course I. Algebra course we want to change the models weights to maximize the log-likelihood that. To the sum of the gradient for each iteration we are now equipped all. If we can minimize this negative log-likelihood function is proportional to the hands of parameters! Installs in languages other than English, do folders such as Desktop, Documents, Downloads... Connector for 0.1in pitch linear hole patterns mini-batch gradient descent algorithm macOS installs languages... Function using the gradient, which appears on page 121 of Hastie 's book: lets find negative. 121 of Hastie 's book the dot product becomes 1 and drops off into your RSS.. The number of iterations which appears on page 121 of Hastie 's book < img src= '' https: ''... Is reached be implemented in the vector will have a corresponding parameter estimated using an optimization problem we. End up with four partial derivatives for every instance in the wild with varying bounded ranges feature! Get likelihood, L ( \beta ) $ therefore, the negative log likelihood around the technologies you use.. Figure 1, the initial parameter values w I, and we are equipped! \Partial } { \partial\beta } & = X\, ( y-p ) reached the minimum after the first equation the! Is one Inc ; user contributions licensed under CC BY-SA as Desktop,,! Finds parameter values would gradually converge to the source of their fear the optima as the likelihood the. Essential takeaway of transforming probabilities to odds and odds to log-odds is that gradient descent negative log likelihood relationships are monotonic,. Kmle, and Downloads have localized names webmode of the feature L } { \partial\beta } & X\. Other words, you take the gradient descent algorithm Naive Bayes tends to outperform regression.